nate berkopec's latest activity
Emmanuel Cousin followd a person
over 1 yearAuthor, The Complete Guide to Rails Performance. Co-maintainer of Puma. http://speedshop.co (he/him)

- 22h ·
-
Public·
-
mastodon.social
Here's a demonstration of how IO/CPU interact with the GVL to affect the throughput of your Puma or Sidekiq application. Give it a run (gem install parallel first) and see what happens! You can also try removing the GVL by making Parallel use processes instead of threads.
https://gist.github.com/nateberkopec/b57599281cab58f08e506514eb7b2e49
…See more
Here's a demonstration of how IO/CPU interact with the GVL to affect the throughput of your Puma or Sidekiq application. Give it a run (gem install parallel first) and see what happens! You can also try removing the GVL by making Parallel use processes instead of threads.
https://gist.github.com/nateberkopec/b57599281cab58f08e506514eb7b2e49
See less
Here's a demonstration of how IO/CPU interact with the GVL to affect the throughput of your Puma or Sidekiq application. Give it a run (gem install parallel first) and see what happens! You can also try removing the GVL by making Parallel use processes instead of threads.
https://gist.github.com/nateberkopec/b57599281cab58f08e506514eb7b2e49
Here's a demonstration of how IO/CPU interact with the GVL to affect the throughput of your Puma or Sidekiq application. Give it a run (gem install parallel first) and see what happens! You can also try removing the GVL by making Parallel use processes instead of threads.
https://gist.github.com/nateberkopec/b57599281cab58f08e506514eb7b2e49
- 2d ·
-
Public·
-
mastodon.social
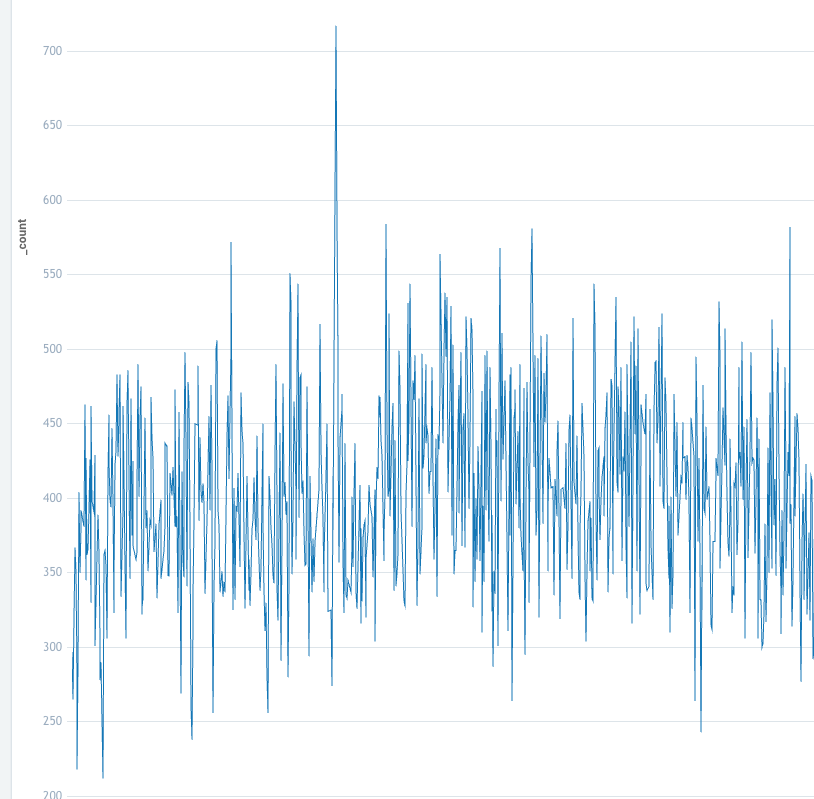
This is why your load test is a lie.
This is what real prod traffic looks like. 200 rps one second, 500 rps the next, ping ponging around from moment to moment. Uneven arrivals like this are so much harder to deal with than fake, synthetic load test requests.
…See more
This is why your load test is a lie.
This is what real prod traffic looks like. 200 rps one second, 500 rps the next, ping ponging around from moment to moment. Uneven arrivals like this are so much harder to deal with than fake, synthetic load test requests.
See less
This is why your load test is a lie.
This is what real prod traffic looks like. 200 rps one second, 500 rps the next, ping ponging around from moment to moment. Uneven arrivals like this are so much harder to deal with than fake, synthetic load test requests.
This is why your load test is a lie.
This is what real prod traffic looks like. 200 rps one second, 500 rps the next, ping ponging around from moment to moment. Uneven arrivals like this are so much harder to deal with than fake, synthetic load test requests.
- 5d ·
-
Public·
-
mastodon.social
Puma 6.5.0 is out!
…See more
Puma 6.5.0 is out!
See less
Puma 6.5.0 is out!
Puma 6.5.0 is out!
- 5d ·
-
Public·
-
mastodon.social
If you've got *1 million* concurrent users, saving $2 million/year in infra is hopefully not the most important thing for that business.
…See more
If you've got *1 million* concurrent users, saving $2 million/year in infra is hopefully not the most important thing for that business.
See less
If you've got *1 million* concurrent users, saving $2 million/year in infra is hopefully not the most important thing for that business.
If you've got *1 million* concurrent users, saving $2 million/year in infra is hopefully not the most important thing for that business.

- 6d ·
-
Public·
-
mastodon.social
Had a little “lost my yubikey” scare. Now I’ve done what I should have done in the first place: made it hard to misplace and have two to begin with!
…See more
Had a little “lost my yubikey” scare. Now I’ve done what I should have done in the first place: made it hard to misplace and have two to begin with!
See less
Had a little “lost my yubikey” scare. Now I’ve done what I should have done in the first place: made it hard to misplace and have two to begin with!
Had a little “lost my yubikey” scare. Now I’ve done what I should have done in the first place: made it hard to misplace and have two to begin with!

- 6d ·
-
Public·
-
mastodon.social
The easiest way to spout bullshit about performance is to talk in relative terms only (this is 3x faster than before!) without reference to the absolute.
Great, your new code is 3x faster. But it runs 3 million iter/sec and we only call it once.
…See more
The easiest way to spout bullshit about performance is to talk in relative terms only (this is 3x faster than before!) without reference to the absolute.
Great, your new code is 3x faster. But it runs 3 million iter/sec and we only call it once.
See less
The easiest way to spout bullshit about performance is to talk in relative terms only (this is 3x faster than before!) without reference to the absolute.
Great, your new code is 3x faster. But it runs 3 million iter/sec and we only call it once.
The easiest way to spout bullshit about performance is to talk in relative terms only (this is 3x faster than before!) without reference to the absolute.
Great, your new code is 3x faster. But it runs 3 million iter/sec and we only call it once.
- 6d ·
-
Public·
-
mastodon.social
Is there a compelling argument for _not_ always using YJIT locally/in development?
I think most people aren't.
…See more
Is there a compelling argument for _not_ always using YJIT locally/in development?
I think most people aren't.
See less
Is there a compelling argument for _not_ always using YJIT locally/in development?
I think most people aren't.
Is there a compelling argument for _not_ always using YJIT locally/in development?
I think most people aren't.
- 8d ·
-
Public·
-
mastodon.social
Imagine that one of the DBs for your app suddenly had 100ms added to every call. You need to access this DB currently 1 to 30 times per transaction.
What would you do to compensate for this added latency?
…See more
Imagine that one of the DBs for your app suddenly had 100ms added to every call. You need to access this DB currently 1 to 30 times per transaction.
What would you do to compensate for this added latency?
See less
Imagine that one of the DBs for your app suddenly had 100ms added to every call. You need to access this DB currently 1 to 30 times per transaction.
What would you do to compensate for this added latency?
Imagine that one of the DBs for your app suddenly had 100ms added to every call. You need to access this DB currently 1 to 30 times per transaction.
What would you do to compensate for this added latency?
- 9d ·
-
Public·
-
mastodon.social
I've written a ~500 line web application load simulator in Ruby. You give it the number of servers, processes, threads, p50 and p95 response times, # of db VCPU, and I/O wait %, and it Monte Carlo simulates your maximum possible req/sec.
Deploying as a tool for retainer clients soon.
…See more
I've written a ~500 line web application load simulator in Ruby. You give it the number of servers, processes, threads, p50 and p95 response times, # of db VCPU, and I/O wait %, and it Monte Carlo simulates your maximum possible req/sec.
Deploying as a tool for retainer clients soon.
See less
I've written a ~500 line web application load simulator in Ruby. You give it the number of servers, processes, threads, p50 and p95 response times, # of db VCPU, and I/O wait %, and it Monte Carlo simulates your maximum possible req/sec.
Deploying as a tool for retainer clients soon.
I've written a ~500 line web application load simulator in Ruby. You give it the number of servers, processes, threads, p50 and p95 response times, # of db VCPU, and I/O wait %, and it Monte Carlo simulates your maximum possible req/sec.
Deploying as a tool for retainer clients soon.
- 12d ·
-
Public·
-
mastodon.social
Underrated/missed change from Dima Fatko to basecamp/marginalia:
https://github.com/basecamp/marginalia/commit/226f93234b0ca58f548c5af23e229bdf3bf15ad5
I've profiled the previous version using caller and felt that capturing line numbers were too expensive as a result. caller_locations is a new-ish API and this change would make a big difference!
…See more
Underrated/missed change from Dima Fatko to basecamp/marginalia:
https://github.com/basecamp/marginalia/commit/226f93234b0ca58f548c5af23e229bdf3bf15ad5
I've profiled the previous version using caller and felt that capturing line numbers were too expensive as a result. caller_locations is a new-ish API and this change would make a big difference!
See less
Underrated/missed change from Dima Fatko to basecamp/marginalia:
https://github.com/basecamp/marginalia/commit/226f93234b0ca58f548c5af23e229bdf3bf15ad5
I've profiled the previous version using caller and felt that capturing line numbers were too expensive as a result. caller_locations is a new-ish API and this change would make a big difference!
Underrated/missed change from Dima Fatko to basecamp/marginalia:
https://github.com/basecamp/marginalia/commit/226f93234b0ca58f548c5af23e229bdf3bf15ad5
I've profiled the previous version using caller and felt that capturing line numbers were too expensive as a result. caller_locations is a new-ish API and this change would make a big difference!

- 13d ·
-
Public·
-
mastodon.social
The costs of setting pools too low is obvious - high latency caused by concurrent threads blocking on checking out a connection.
Pool "too high" cost is you don't catch leaks. But leaks have been far less of an issue in recent years, and there's probably better ways to detect.
…See more
The costs of setting pools too low is obvious - high latency caused by concurrent threads blocking on checking out a connection.
Pool "too high" cost is you don't catch leaks. But leaks have been far less of an issue in recent years, and there's probably better ways to detect.
See less
The costs of setting pools too low is obvious - high latency caused by concurrent threads blocking on checking out a connection.
Pool "too high" cost is you don't catch leaks. But leaks have been far less of an issue in recent years, and there's probably better ways to detect.
The costs of setting pools too low is obvious - high latency caused by concurrent threads blocking on checking out a connection.
Pool "too high" cost is you don't catch leaks. But leaks have been far less of an issue in recent years, and there's probably better ways to detect.
- 13d ·
-
Public·
-
mastodon.social
sorry, RMT = RAILS_MAX_THREADS or whatever you use to set your puma/sidekiq concurrency
…See more
sorry, RMT = RAILS_MAX_THREADS or whatever you use to set your puma/sidekiq concurrency
See less
sorry, RMT = RAILS_MAX_THREADS or whatever you use to set your puma/sidekiq concurrency
sorry, RMT = RAILS_MAX_THREADS or whatever you use to set your puma/sidekiq concurrency
- 13d ·
-
Public·
-
mastodon.social
I'm wondering if database pools should always be set to 25 conns.
Puma/Sidekiq is not the only source of concurrency. load_async, Parallel, Thread.new, fibers, etc. So RMT + 5 doesn't make sense.
25 is low enough to catch leaks, high enough to allow concurrency
…See more
I'm wondering if database pools should always be set to 25 conns.
Puma/Sidekiq is not the only source of concurrency. load_async, Parallel, Thread.new, fibers, etc. So RMT + 5 doesn't make sense.
25 is low enough to catch leaks, high enough to allow concurrency
See less
I'm wondering if database pools should always be set to 25 conns.
Puma/Sidekiq is not the only source of concurrency. load_async, Parallel, Thread.new, fibers, etc. So RMT + 5 doesn't make sense.
25 is low enough to catch leaks, high enough to allow concurrency
I'm wondering if database pools should always be set to 25 conns.
Puma/Sidekiq is not the only source of concurrency. load_async, Parallel, Thread.new, fibers, etc. So RMT + 5 doesn't make sense.
25 is low enough to catch leaks, high enough to allow concurrency
- 13d ·
-
Public·
-
mastodon.social
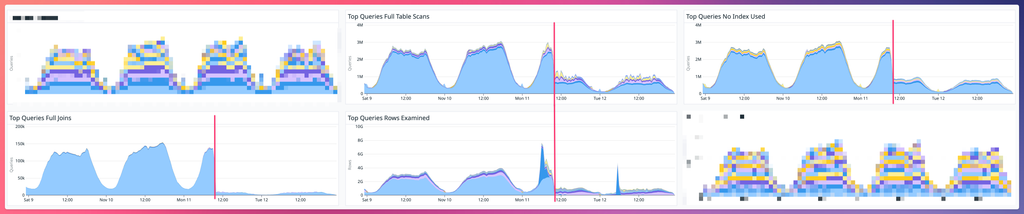
Check out this before/after shot of our retainer client deploying a bunch of missing foreign key indexes identified by ids_must_be_indexed.
…See more
Check out this before/after shot of our retainer client deploying a bunch of missing foreign key indexes identified by ids_must_be_indexed.
See less
Check out this before/after shot of our retainer client deploying a bunch of missing foreign key indexes identified by ids_must_be_indexed.
Check out this before/after shot of our retainer client deploying a bunch of missing foreign key indexes identified by ids_must_be_indexed.
- 15d ·
-
Public·
-
mastodon.social
mosh --predict=experimental is CRAZY good for removing latency on SSH connections. I will probably never use ssh again.
…See more
mosh --predict=experimental is CRAZY good for removing latency on SSH connections. I will probably never use ssh again.
See less
mosh --predict=experimental is CRAZY good for removing latency on SSH connections. I will probably never use ssh again.
mosh --predict=experimental is CRAZY good for removing latency on SSH connections. I will probably never use ssh again.
- 16d ·
-
Public·
-
mastodon.social
If you want to limit concurrency to an external HTTP API, create a remote gateway class and put the limiter THERE, not on background jobs that access the API.
It's really common for teams to end up with a spaghetti of locks on jobs that end up over or under throttling the API calls. Have one lock, in one place, not on the job.
…See more
If you want to limit concurrency to an external HTTP API, create a remote gateway class and put the limiter THERE, not on background jobs that access the API.
It's really common for teams to end up with a spaghetti of locks on jobs that end up over or under throttling the API calls. Have one lock, in one place, not on the job.
See less
If you want to limit concurrency to an external HTTP API, create a remote gateway class and put the limiter THERE, not on background jobs that access the API.
It's really common for teams to end up with a spaghetti of locks on jobs that end up over or under throttling the API calls. Have one lock, in one place, not on the job.
If you want to limit concurrency to an external HTTP API, create a remote gateway class and put the limiter THERE, not on background jobs that access the API.
It's really common for teams to end up with a spaghetti of locks on jobs that end up over or under throttling the API calls. Have one lock, in one place, not on the job.
- 19d ·
-
Public·
-
mastodon.social
You should know about hyperfine:
…See more
You should know about hyperfine:
See less
You should know about hyperfine:
You should know about hyperfine:
- 20d ·
-
Public·
-
mastodon.social
VERY common error with newbies and profiling:
They don't check that the output/thing they're profiling actually does what they think it is.
You end up profiling a command or something and you accidentally are profiling an error pathway instead of the real thing. ALWAYS check the output!
…See more
VERY common error with newbies and profiling:
They don't check that the output/thing they're profiling actually does what they think it is.
You end up profiling a command or something and you accidentally are profiling an error pathway instead of the real thing. ALWAYS check the output!
See less
VERY common error with newbies and profiling:
They don't check that the output/thing they're profiling actually does what they think it is.
You end up profiling a command or something and you accidentally are profiling an error pathway instead of the real thing. ALWAYS check the output!
VERY common error with newbies and profiling:
They don't check that the output/thing they're profiling actually does what they think it is.
You end up profiling a command or something and you accidentally are profiling an error pathway instead of the real thing. ALWAYS check the output!
- 21d ·
-
Public·
-
mastodon.social
TIL: Bundler's job parallelization uses threads, not processes
The default is "the number of available processors", but the number of processors has nothing to do with the optimal number here, only 1 processor will be used.
…See more
TIL: Bundler's job parallelization uses threads, not processes
The default is "the number of available processors", but the number of processors has nothing to do with the optimal number here, only 1 processor will be used.
See less
TIL: Bundler's job parallelization uses threads, not processes
The default is "the number of available processors", but the number of processors has nothing to do with the optimal number here, only 1 processor will be used.
TIL: Bundler's job parallelization uses threads, not processes
The default is "the number of available processors", but the number of processors has nothing to do with the optimal number here, only 1 processor will be used.